ECMAScript 2015 introduced several new data structures such as Map, Set, WeakSet, and WeakMap, all of which use hash tables under the hood. This post details the recent improvements in how V8 v6.3+ stores the keys in hash tables.
Hash code #
A hash function is used to map a given key to a location in the hash table. A hash code is the result of running this hash function over a given key.
In V8, the hash code is just a random number, independent of the object value. Therefore, we can’t recompute it, meaning we must store it.
For JavaScript objects that were used as keys, previously, the hash code was stored as a private symbol on the object. A private symbol in V8 is similar to a Symbol, except that it’s not enumerable and doesn’t leak to userspace JavaScript.
function GetObjectHash(key) {
let hash = key[hashCodeSymbol];
if (IS_UNDEFINED(hash)) {
hash = (MathRandom() * 0x40000000) | 0;
if (hash === 0) hash = 1;
key[hashCodeSymbol] = hash;
}
return hash;
}
This worked well because we didn’t have to reserve memory for a hash code field until the object was added to a hash table, at which point a new private symbol was stored on the object.
V8 could also optimize the hash code symbol lookup just like any other property lookup using the IC system, providing very fast lookups for the hash code. This works well for monomorphic IC lookups, when the keys have the same hidden class. However, most real-world code doesn’t follow this pattern, and often keys have different hidden classes, leading to slow megamorphic IC lookups of the hash code.
Another problem with the private symbol approach was that it triggered a hidden class transition in the key on storing the hash code. This resulted in poor polymorphic code not just for the hash code lookup but also for other property lookups on the key and deoptimization from optimized code.
JavaScript object backing stores #
A JavaScript object (JSObject) in V8 uses two words (apart from its header): one word for storing a pointer to the elements backing store, and another word for storing a pointer to the properties backing store.
The elements backing store is used for storing properties that look like array indices, whereas the properties backing store is used for storing properties whose keys are strings or symbols. See this V8 blog post by Camillo Bruni for more information about these backing stores.
const x = {};
x[1] = 'bar';
x['foo'] = 'bar';
Hiding the hash code #
The easiest solution to storing the hash code would be to extend the size of a JavaScript object by one word and store the hash code directly on the object. However, this would waste memory for objects that aren’t added to a hash table. Instead, we could try to store the hash code in the elements store or properties store.
The elements backing store is an array containing its length and all the elements. There’s not much to be done here, as storing the hashcode in a reserved slot (like the 0th index) would still waste memory when we don’t use the object as a key in a hash table.
Let’s look at the properties backing store. There are two kinds of data structures used as a properties backing store: arrays and dictionaries.
Unlike the array used in the elements backing store which does not have an upper limit, the array used in the properties backing store has an upper limit of 1022 values. V8 transitions to using a dictionary on exceeding this limit for performance reasons. (I’m slightly simplifying this — V8 can also use a dictionary in other cases, but there is a fixed upper limit on the number of values that can be stored in the array.)
So, there are three possible states for the properties backing store:
- empty (no properties)
- array (can store up to 1022 values)
- dictionary
Let’s discuss each of these.
The properties backing store is empty #
For the empty case, we can directly store the hash code in this offset on the JSObject.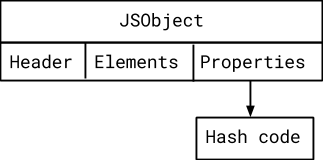
The properties backing store is an array #
V8 represents integers less than 231 (on 32-bit systems) unboxed, as Smis. In a Smi, the least significant bit is a tag used to distinguish it from pointers, while the remaining 31 bits hold the actual integer value.
Normally, arrays store their length as a Smi. Since we know that the maximum capacity of this array is only 1022, we only need 10 bits to store the length. We can use the remaining 21 bits to store the hash code!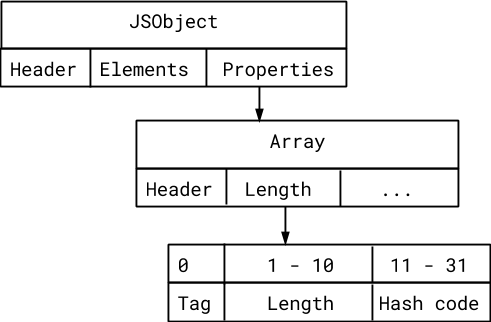
The properties backing store is a dictionary #
For the dictionary case, we increase the dictionary size by 1 word to store the hashcode in a dedicated slot at the beginning of the dictionary. We get away with potentially wasting a word of memory in this case, because the proportional increase in size isn’t as big as in the array case.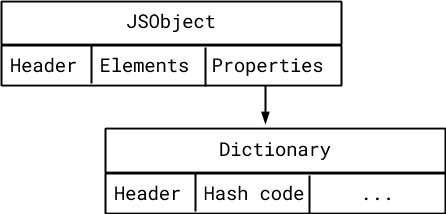
With these changes, the hash code lookup no longer has to go through the complex JavaScript property lookup machinery.
The SixSpeed benchmark tracks the performance of Map and Set, and these changes resulted in a ~500% improvement.
This change caused a 5% improvement on the Basic benchmark in ARES6 as well.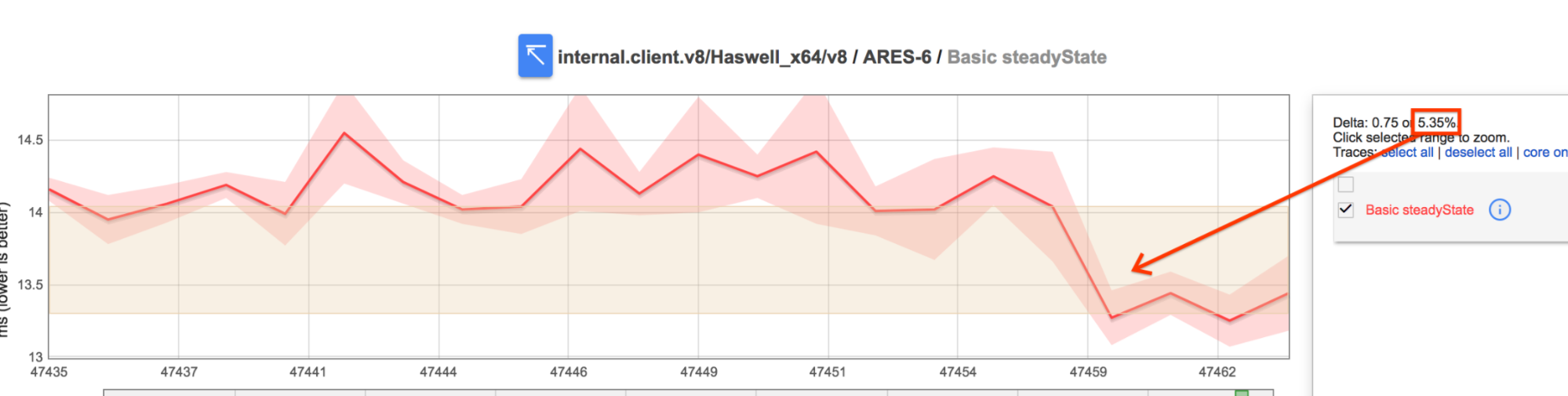
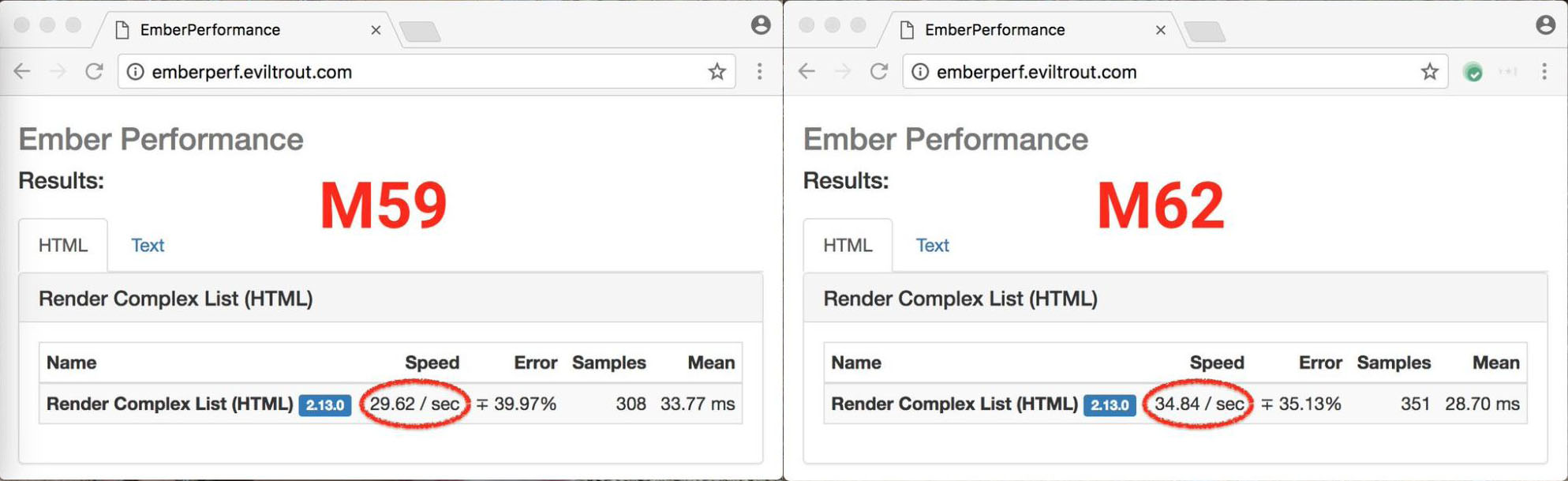
This also resulted in an 18% improvement in one of the benchmarks in the Emberperf benchmark suite that tests Ember.js.