During his three-months internship on the V8 team, Hai Dang worked on improving the performance of [...array], [...string], [...set], [...map.keys()], and [...map.values()] (when the spread elements are at the start of the array literal). He even made Array.from(iterable) much faster as well. This article explains some of the gory details of his changes, which are included in V8 starting with v7.2.
Spread elements #
Spread elements are components of array literals that have the form ...iterable. They were introduced in ES2015 as a way to create arrays from iterable objects. For example, the array literal [1, ...arr, 4, ...b] creates an array whose first element is 1 followed by the elements of the array arr, then 4, and finally the elements of the array b:
const a = [2, 3];
const b = [5, 6, 7];
const result = [1, ...a, 4, ...b];
As another example, any string can be spread to create an array of its characters (Unicode code points):
const str = 'こんにちは';
const result = [...str];
Similarly, any set can be spread to create an array of its elements, sorted by insertion order:
const s = new Set();
s.add('V8');
s.add('TurboFan');
const result = [...s];
In general, the spread elements syntax ...x in an array literal assumes that x provides an iterator (accessible through x[Symbol.iterator]()). This iterator is then used to obtain the elements to be inserted into the resulting array.
The simple use case of spreading an array arr into a new array, without adding any further elements before or behind, [...arr], is considered a concise, idiomatic way to shallow-clone arr in ES2015. Unfortunately, in V8, the performance of this idiom lagged far behind its ES5 counterpart. The goal of Hai’s internship was to change that!
Why is (or were!) spread elements slow? #
There are many ways to shallow-clone an array arr. For instance, you can use arr.slice(), or arr.concat(), or [...arr]. Or, you can write your own clone function that employs a standard for-loop:
function clone(arr) {
const result = new Array(arr.length);
for (let i = 0; i < arr.length; i++) {
result[i] = arr[i];
}
return result;
}
Ideally, all these options would have similar performance characteristics. Unfortunately, if you pick [...arr] in V8, it is (or was) likely to be slower than clone! The reason is that V8 essentially transpiles [...arr] into an iteration like the following:
function(arr) {
const result = [];
const iterator = arr[Symbol.iterator]();
const next = iterator.next;
for ( ; ; ) {
const iteratorResult = next.call(iterator);
if (iteratorResult.done) break;
result.push(iteratorResult.value);
}
return result;
}
This code is generally slower than clone for a few reasons:
- It needs to create the
iterator at the beginning by loading and evaluating the Symbol.iterator property. - It needs to create and query the
iteratorResult object at every step. - It grows the
result array at every step of the iteration by calling push, thus repeatedly reallocating the backing store.
The reason for using such an implementation is that, as mentioned earlier, spreading can be done not only on arrays but, in fact, on arbitrary iterable objects, and must follow the iteration protocol. Nevertheless, V8 should be smart enough to recognize if the object being spread is an array such that it can perform the elements extraction at a lower level and thereby:
- avoid the creation of the iterator object,
- avoid the creation of the iterator result objects, and
- avoid continuously growing and thus reallocating the result array (we know the number of elements in advance).
We implemented this simple idea using CSA for fast arrays, i.e. arrays with one of the six most common elements kinds. The optimization applies for the common real-world scenario where the spread occurs at the start of the array literal, e.g. [...foo]. As shown in the graph below, this new fast path yields roughly a 3× performance improvement for spreading an array of length 100,000, making it about 25% faster than the hand-written clone loop.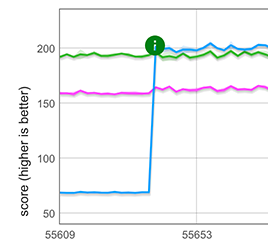 Performance improvement of spreading a fast array
Performance improvement of spreading a fast array
Note: While not shown here, the fast path also applies when the spread elements are followed by other components (e.g. [...arr, 1, 2, 3]), but not when they are preceded by others (e.g. [1, 2, 3, ...arr]).
Tread carefully down that fast path #
That’s clearly an impressive speedup, but we must be very careful about when it is correct to take this fast path: JavaScript allows the programmer to modify the iteration behavior of objects (even arrays) in various ways. Because spread elements are specified to use the iteration protocol, we need to ensure that such modifications are respected. We do so by avoiding the fast path completely whenever the original iteration machinery has been mutated. For example, this includes situations like the following.
Own Symbol.iterator property #
Normally, an array arr does not have its own Symbol.iterator property, so when looking up that symbol, it will be found on the array’s prototype. In the example below, the prototype is bypassed by defining the Symbol.iterator property directly on arr itself. After this modification, looking up Symbol.iterator on arr results in an empty iterator, and thus the spread of arr yields no elements and the array literal evaluates to an empty array.
const arr = [1, 2, 3];
arr[Symbol.iterator] = function() {
return { next: function() { return { done: true }; } };
};
const result = [...arr];
Modified %ArrayIteratorPrototype% #
The next method can also be modified directly on %ArrayIteratorPrototype%, the prototype of array iterators (which affects all arrays).
Object.getPrototypeOf([][Symbol.iterator]()).next = function() {
return { done: true };
}
const arr = [1, 2, 3];
const result = [...arr];
Dealing with holey arrays #
Extra care is also needed when copying arrays with holes, i.e., arrays like ['a', , 'c'] that are missing some elements. Spreading such an array, by virtue of adhering to the iteration protocol, does not preserve the holes but instead fills them with the values found in the array’s prototype at the corresponding indices. By default there are no elements in an array’s prototype, which means that any holes are filled with undefined. For example, [...['a', , 'c']] evaluates to a new array ['a', undefined, 'c'].
Our fast path is smart enough to handle holes in this default situation. Instead of blindly copying the input array’s backing store, it watches out for holes and takes care of converting them to undefined values. The graph below contains measurements for an input array of length 100,000 containing only (tagged) 600 integers — the rest are holes. It shows that spreading such a holey array is now over 4× faster than using the clone function. (They used to be roughly on par, but this is not shown in the graph).
Note that although slice is included in this graph, the comparison with it is unfair because slice has a different semantics for holey arrays: it preserves all the holes, so it has much less work to do.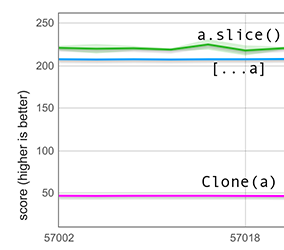 Performance improvement of spreading a holey array of integers (
Performance improvement of spreading a holey array of integers (HOLEY_SMI_ELEMENTS)
The filling of holes with undefined that our fast path has to perform is not as simple as it sounds: it may require converting the whole array to a different elements kind. The next graph measures such a situation. The setup is the same as above, except that this time the 600 array elements are unboxed doubles and the array has the HOLEY_DOUBLE_ELEMENTS elements kind. Since this elements kind cannot hold tagged values such as undefined, spreading involves a costly elements kind transition, which is why the score for [...a] is much lower than in the previous graph. Nevertheless, it is still much faster than clone(a).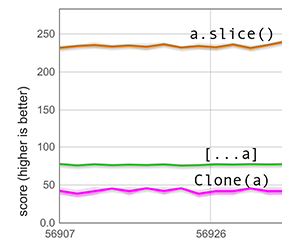 Performance improvement of spreading a holey array of doubles (
Performance improvement of spreading a holey array of doubles (HOLEY_DOUBLE_ELEMENTS)
Spreading strings, sets, and maps #
The idea of skipping the iterator object and avoiding growing the result array equally applies to spreading other standard data types. Indeed, we implemented similar fast paths for primitive strings, for sets, and for maps, each time taking care to bypass them in the presence of modified iteration behavior.
Concerning sets, the fast path supports not only spreading a set directly ([...set]), but also spreading its keys iterator ([...set.keys()]) and its values iterator ([...set.values()]). In our micro-benchmarks, these operations are now about 18× faster than before.
The fast path for maps is similar but does not support spreading a map directly ([...map]), because we consider this an uncommon operation. For the same reason, neither fast path supports the entries() iterator. In our micro-benchmarks, these operations are now about 14× faster than before.
For spreading strings ([...string]), we measured a roughly 5× improvement, as shown in the graph below by the purple and green lines. Note that this is even faster than a TurboFan-optimized for-of-loop (TurboFan understands string iteration and can generate optimized code for it), represented by the blue and pink lines. The reason for having two plots in each case is that the micro-benchmarks operate on two different string representations (one-byte strings and two-byte strings).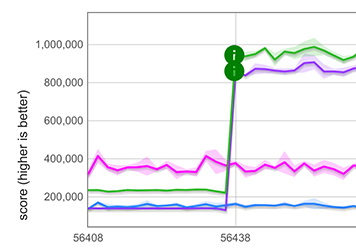 Performance improvement of spreading a string
Performance improvement of spreading a string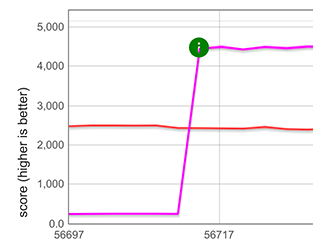 Performance improvement of spreading a set with 100,000 integers (magenta, about 18×), shown here in comparison with a
Performance improvement of spreading a set with 100,000 integers (magenta, about 18×), shown here in comparison with a for-of loop (red)
Fortunately, our fast paths for spread elements can be reused for Array.from in the case where Array.from is called with an iterable object and without a mapping function, for example, Array.from([1, 2, 3]). The reuse is possible because in this case, the behavior of Array.from is exactly the same as that of spreading. It results in an enormous performance improvement, shown below for an array with 100 doubles.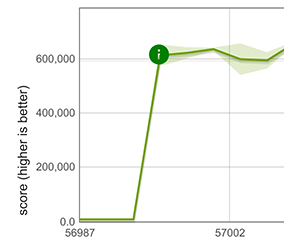 Performance improvement of
Performance improvement of Array.from(array) where array contains 100 doubles
Conclusion #
V8 v7.2 / Chrome 72 greatly improves the performance of spread elements when they occur at the front of the array literal, for example [...x] or [...x, 1, 2]. The improvement applies to spreading arrays, primitive strings, sets, maps keys, maps values, and — by extension — to Array.from(x).