JavaScript objects in V8 are allocated on a heap managed by V8’s garbage collector. In previous blog posts we have already talked about how we reduce garbage collection pause times (more than once) and memory consumption. In this blog post we introduce the parallel Scavenger, one of the latest features of Orinoco, V8’s mostly concurrent and parallel garbage collector and discuss design decisions and alternative approaches we implemented on the way.
V8 partitions its managed heap into generations where objects are initially allocated in the “nursery” of the young generation. Upon surviving a garbage collection, objects are copied into the intermediate generation, which is still part of the young generation. After surviving another garbage collection, these objects are moved into the old generation (see Figure 1). V8 implements two garbage collectors: one that frequently collects the young generation, and one that collects the full heap including both the young and old generation. Old-to-young generation references are roots for the young generation garbage collection. These references are recorded to provide efficient root identification and reference updates when objects are moved.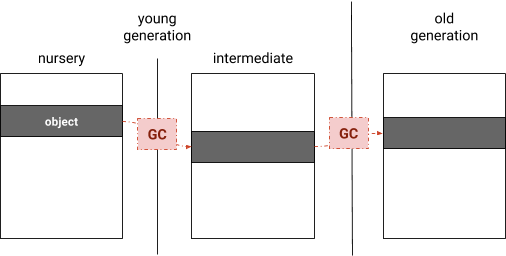 Figure 1: Generational garbage collection
Figure 1: Generational garbage collection
Since the young generation is relatively small (up to 16MiB in V8) it fills up quickly with objects and requires frequent collections. Until M62, V8 used a Cheney semispace copying garbage collector (see below) that divides the young generation into two halves. During JavaScript execution only one half of the young generation is available for allocating objects, while the other half remains empty. During a young garbage collection, live objects are copied from one half to the other half, compacting the memory on the fly. Live objects that have already been copied once are considered part of the intermediate generation and are promoted to the old generation.
Starting with v6.2, V8 switched the default algorithm for collecting the young generation to a parallel Scavenger, similar to Halstead’s semispace copying collector with the difference that V8 makes use of dynamic instead of static work stealing across multiple threads. In the following we explain three algorithms: a) the single-threaded Cheney semispace copying collector, b) a parallel Mark-Evacuate scheme, and c) the parallel Scavenger.
Single-threaded Cheney’s Semispace Copy #
Until v6.2, V8 used Cheney’s semispace copying algorithm which is well-suited for both single-core execution and a generational scheme. Before a young generation collection, both semispace halves of memory are committed and assigned proper labels: the pages containing the current set of objects are called from-space while the pages that objects are copied to are called to-space.
The Scavenger considers references in the call stack and references from the old to the young generation as roots. Figure 2 illustrates the algorithm where initially the Scavenger scans these roots and copies objects reachable in the from-space that have not yet been copied to the to-space. Objects that have already survived a garbage collection are promoted (moved) to the old generation. After root scanning and the first round of copying, the objects in the newly allocated to-space are scanned for references. Similarly, all promoted objects are scanned for new references to from-space. These three phases are interleaved on the main thread. The algorithm continues until no more new objects are reachable from either to-space or the old generation. At this point the from-space only contains unreachable objects, i.e., it only contains garbage.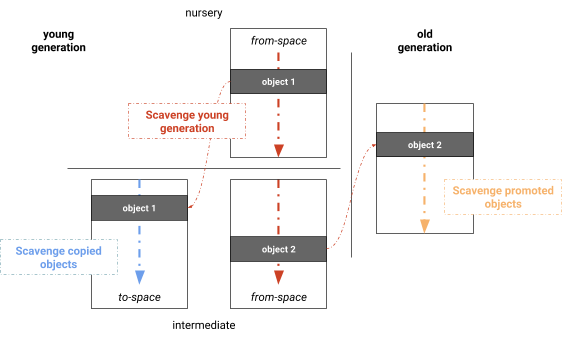 Figure 2: Cheney’s semispace copying algorithm used for young generation garbage collections in V8
Figure 2: Cheney’s semispace copying algorithm used for young generation garbage collections in V8 Processing
Processing
Parallel Mark-Evacuate #
We experimented with a parallel Mark-Evacuate algorithm based on the V8’s full Mark-Sweep-Compact collector. The main advantage is leveraging the already existing garbage collection infrastructure from the full Mark-Sweep-Compact collector. The algorithm consists of three phases: marking, copying, and updating pointers, as shown in Figure 3. To avoid sweeping pages in the young generation to maintain free lists, the young generation is still maintained using a semispace that is always kept compact by copying live objects into to-space during garbage collection. The young generation is initially marked in parallel. After marking, live objects are copied in parallel to their corresponding spaces. Work is distributed based on logical pages. Threads participating in copying keep their own local allocation buffers (LABs) which are merged upon finishing copying. After copying, the same parallelization scheme is applied for updating inter-object pointers. These three phases are performed in lockstep, i.e., while the phases themselves are performed in parallel, threads have to synchronize before continuing to the next phase.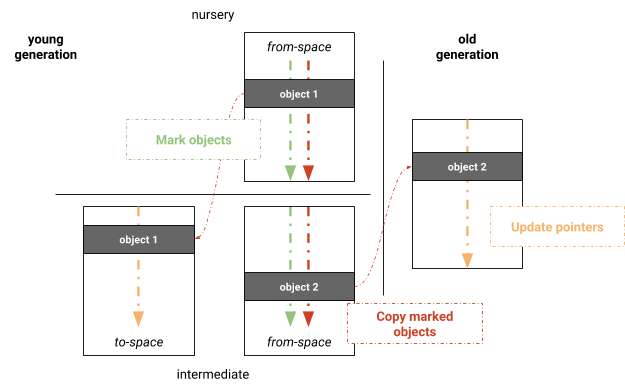 Figure 3: Young Generation Parallel Mark-Evacuate garbage collection in V8
Figure 3: Young Generation Parallel Mark-Evacuate garbage collection in V8 Processing
Processing
Parallel Scavenge #
The parallel Mark-Evacuate collector separates the phases of computing liveness, copying live objects, and updating pointers. An obvious optimization is to merge these phases, resulting in an algorithm that marks, copies, and updates pointers at the same time. By merging those phases we actually get the parallel Scavenger used by V8, which is a version similar to Halstead’s semispace collector with the difference that V8 uses dynamic work stealing and a simple load balancing mechanism for scanning the roots (see Figure 4). Like the single-threaded Cheney algorithm, the phases are: scanning for roots, copying within the young generation, promoting to the old generation, and updating pointers. We found that the majority of the root set is usually the references from the old generation to the young generation. In our implementation, remembered sets are maintained per-page, which naturally distributes the roots set among garbage collection threads. Objects are then processed in parallel. Newly-found objects are added to a global work list from which garbage collection threads can steal. This work list provides fast task local storage as well as global storage for sharing work. A barrier makes sure that tasks do not prematurely terminate when the sub graph currently processed is not suitable for work stealing (e.g. a linear chain of objects). All phases are performed in parallel and interleaved on each task, maximizing the utilization of worker tasks.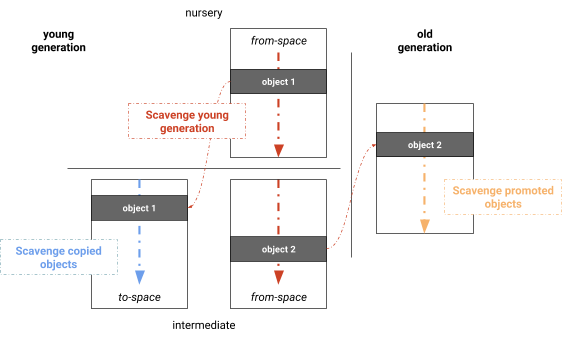 Figure 4: Young generation parallel Scavenger in V8
Figure 4: Young generation parallel Scavenger in V8 Processing
Processing
Results and outcome #
The Scavenger algorithm was initially designed having optimal single-core performance in mind. The world has changed since then. CPU cores are often plentiful, even on low-end mobile devices. More importantly, often these cores are actually up and running. To fully utilize these cores, one of the last sequential components of V8’s garbage collector, the Scavenger, had to be modernized.
The big advantage of a parallel Mark-Evacuate collector is that exact liveness information is available. This information can e.g. be used to avoid copying at all by just moving and relinking pages that contain mostly live objects which is also performed by the full Mark-Sweep-Compact collector. In practice, however, this was mostly observable on synthetic benchmarks and rarely showed up on real websites. The downside of the parallel Mark-Evacuate collector is the overhead of performing three separate lockstep phases. This overhead is especially noticeable when the garbage collector is invoked on a heap with mostly dead objects, which is the case on many real-world webpages. Note that invoking garbage collections on heaps with mostly dead objects is actually the ideal scenario, as garbage collection is usually bounded by the size of live objects.
The parallel Scavenger closes this performance gap by providing performance that is close to the optimized Cheney algorithm on small or almost empty heaps while still providing a high throughput in case the heaps get larger with lots of live objects.
V8 supports, among many other platforms, as Arm big.LITTLE. While offloading work on little cores benefits battery lifetime, it can lead to stalling on the main thread when work packages for little cores are too big. We observed that page-level parallelism does not necessarily load balance work on big.LITTLE for a young generation garbage collection due to the limited number of pages. The Scavenger naturally solves this issue by providing medium-grained synchronization using explicit work lists and work stealing.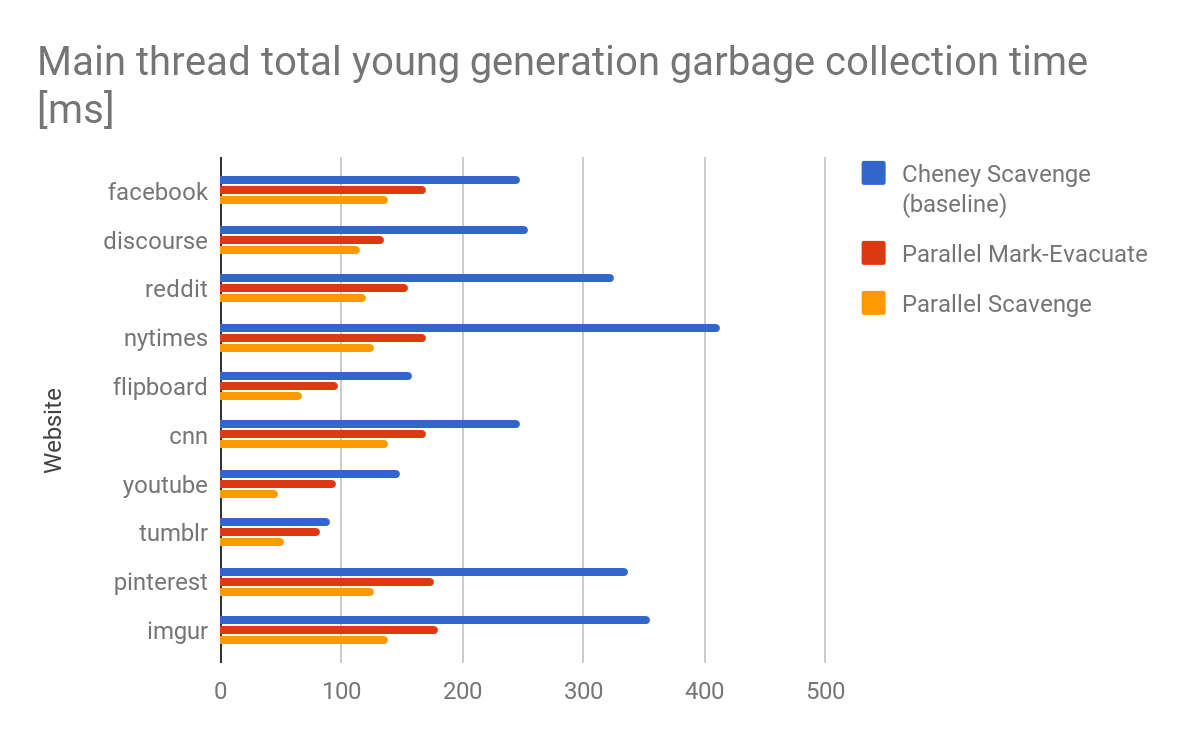 Figure 5: Total young generation garbage collection time (in ms) across various websites
Figure 5: Total young generation garbage collection time (in ms) across various websites
V8 now ships with the parallel Scavenger which reduces the main thread young generation garbage collection total time by about 20%–50% across a large set of benchmarks (details on our perf waterfalls). Figure 5 shows a comparison of the implementations across various real-world websites, showing improvements around 55% (2×). Similar improvements can be observed on maximum and average pause time while maintaining minimum pause time. The parallel Mark-Evacuate collector scheme still has potential for optimization. Stay tuned if you want to find out what happens next.