In a previous blog post, we introduced the problem of jank caused by garbage collection interrupting a smooth browsing experience. In this blog post we introduce three optimizations that lay the groundwork for a new garbage collector in V8, codenamed Orinoco. Orinoco is based on the idea that implementing a mostly parallel and concurrent garbage collector without strict generational boundaries will reduce garbage collection jank and memory consumption while providing high throughput. Instead of implementing Orinoco behind a flag as a separate garbage collector, we decided to ship features of Orinoco incrementally on V8 tip of tree to benefit users immediately. The three features discussed in this post are parallel compaction, parallel remembered set processing, and black allocation.
V8 implements a generational garbage collector where objects may move within the young generation, from the young to the old generation, and within the old generation. Moving objects is expensive since the underlying memory of objects needs to be copied to new locations and the pointers to those objects are also subject to updating. Figure 1 shows the phases and how they were executed before Orinoco. Essentially, objects were moved first and then pointers between those objects were updated afterwards, all in sequential order, resulting in observable jank.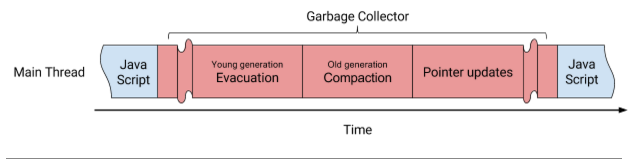 Figure 1: Sequential moving of objects and updating pointers
Figure 1: Sequential moving of objects and updating pointers
V8 partitions its heap memory into fixed-size chunks, called pages, that are assigned to either young or old generation space. Objects are initially allocated in the young generation. Upon garbage collection, live objects are moved within the young generation once. Objects that survive another garbage collection are promoted to the old generation. For both phases, which we call collectively young generation evacuation, we parallelize the copying of memory based on pages. Within the young generation, moving objects always involves allocating memory on fresh pages (and releasing the old pages), leaving behind a compact memory layout. In the old generation this process happens in a slightly different manner, since dead memory leaves behind unusable holes (or fragmentation). Some of these holes can be reused via free lists, but others are left behind, requiring compaction to move live objects to a better packed (potentially new) page. Similar to the young generation this process is parallelized on page-level.
Since there are no dependencies between young generation evacuation and old generation compaction, Orinoco now performs these phases in parallel, as shown in Figure 2. The result of these improvements is a reduction of compaction time of 75% from ~7ms to under 2ms on average.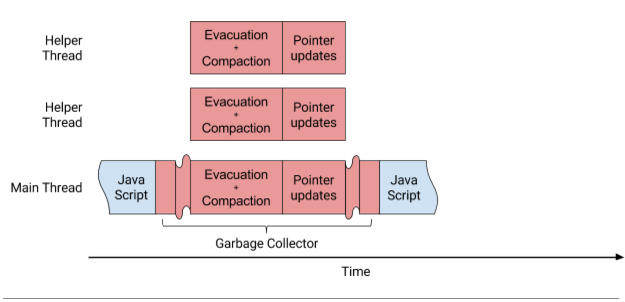 Figure 2: Parallel moving of objects and updating pointers
Figure 2: Parallel moving of objects and updating pointers
The second optimization introduced by Orinoco improves how garbage collection tracks pointers. When an object moves location on the heap, the garbage collector has to find all pointers that contain the old location of the moved object and update them with the new location. Since iterating through the heap to find the pointers would be very slow, V8 uses a data structure called a remembered set to keep track of all the interesting pointers on the heap. A pointer is interesting if it points to an object that may move during garbage collection. For example, all pointers from the old generation to the new generation are interesting because new generation objects move on every garbage collection. Pointers to objects in heavily fragmented pages are also interesting because these objects will move to other pages during compaction.
Previously, V8 implemented remembered sets as arrays of pointer addresses, or store buffers. There was one store buffer for the young generation and one for each of the fragmented old generation pages. The store buffer of a page contains addresses of all incoming pointers as shown in Figure 3. Entries are appended to a store buffer in a write barrier, which guards write operations in JavaScript code. This may result in duplicate entries since a store buffer may include a pointer multiple times and two different store buffers may include the same pointer. Duplicate entries make parallelization of the pointer update phase difficult because of the data race caused by two threads trying to update the same pointer.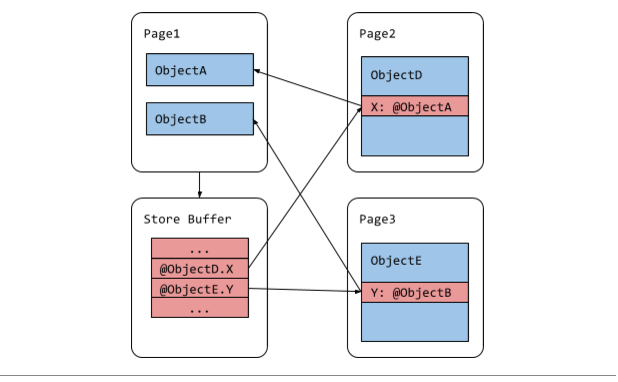 Figure 3: Old remembered set
Figure 3: Old remembered set
Orinoco removes this complexity by reorganizing the remembered set to simplify parallelization and make sure that threads get disjoint sets of pointers to update. Instead of storing incoming interesting pointers in an array, each page now stores the offsets of interesting pointers originating from that page in buckets of bitmaps as shown in Figure 4. Each bucket is either empty or points to a bitmap of a fixed length. A bit in the bitmap corresponds to a pointer offset in the page. If a bit is set then the pointer is interesting and is in the remembered set. Using this data-structure we can parallelize pointer updates based on pages. The absence of duplicate entries and the dense representation of pointers also allowed us to remove complex code for handling remembered set overflow. In our long running Gmail benchmark, this change reduced the maximum pause time of compacting garbage collection by 45% from 42ms to 23 ms.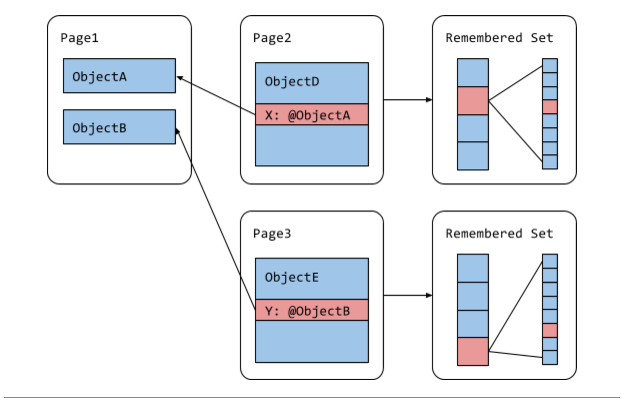 Figure 4: New remembered set
Figure 4: New remembered set
The third optimization that Orinoco introduces is black allocation, an improvement to the marking phase of the garbage collector. Black allocation (shipped in V8 5.1) is a garbage collection technique in which all objects allocated in the old generation (e.g. pre-tenured allocations or promoted objects by the garbage collector) are marked black immediately in order to designate them as "live". The intuition behind black allocation is that objects allocated in the old generation are likely long living. Therefore, objects that were recently allocated in the old generation should at least survive the next old generation garbage collection, otherwise they were falsely promoted. After coloring newly allocated objects black the garbage collector will not visit them. We speed up coloring of black objects by allocating them on black pages where all objects are black by default. Another benefit of black pages is that they do not have to be swept, since all objects allocated on them are (by definition) live. Black allocation speeds up incremental marking progress since marking work does not increase with new allocations. The impact of black allocation is clearly visible on the Octane Splay benchmark where the throughput and latency score improved by about 30% while using about 20% less memory due to faster marking progress and less garbage collection work overall.
We plan to roll out more Orinoco features soon. Stay tuned, we are still tinkering!