At V8, we're constantly striving to improve JavaScript performance. As part of this effort, we recently revisited the JetStream2 benchmark suite to eliminate performance cliffs. This post details a specific optimization we made that yielded a significant 2.5x improvement in the async-fs benchmark, contributing to a noticeable boost in the overall score. The optimization was inspired by the benchmark, but such patterns do appear in real-world code.
The target async-fs and a peculiar Math.random #
The async-fs benchmark, as its name suggests, is a JavaScript file system implementation, focusing on asynchronous operations. However, a surprising performance bottleneck exists: the implementation of Math.random. It uses a custom, deterministic implementation of Math.random for consistent results across runs. The implementation is:
let seed;
Math.random = (function() {
return function () {
seed = ((seed + 0x7ed55d16) + (seed << 12)) & 0xffffffff;
seed = ((seed ^ 0xc761c23c) ^ (seed >>> 19)) & 0xffffffff;
seed = ((seed + 0x165667b1) + (seed << 5)) & 0xffffffff;
seed = ((seed + 0xd3a2646c) ^ (seed << 9)) & 0xffffffff;
seed = ((seed + 0xfd7046c5) + (seed << 3)) & 0xffffffff;
seed = ((seed ^ 0xb55a4f09) ^ (seed >>> 16)) & 0xffffffff;
return (seed & 0xfffffff) / 0x10000000;
};
})();
The key variable here is seed. It's updated on every call to Math.random, generating the pseudo-random sequence. Crucially, here seed is stored in a ScriptContext.
A ScriptContext serves as a storage location for values accessible within a particular script. Internally, this context is represented as an array of V8's tagged values. On the default V8 configuration for 64-bit systems, each of these tagged values occupies 32 bits. The least significant bit of each value acts as a tag. A 0 indicates a 31-bit Small Integer (SMI). The actual integer value is stored directly, left-shifted by one bit. A 1 indicates a compressed pointer to a heap object, where the compressed pointer value is incremented by one.
ScriptContext layout: blue slots are pointers to the context metadata and to the global object (NativeContext). The yellow slot indicates an untagged double-precision floating-point value.
This tagging differentiates how numbers are stored. SMIs reside directly in the ScriptContext. Larger numbers or those with decimal parts are stored indirectly as immutable HeapNumber objects on the heap (a 64-bit double), with the ScriptContext holding a compressed pointer to them. This approach efficiently handles various numeric types while optimizing for the common SMI case.
The bottleneck #
Profiling Math.random revealed two major performance issues:
HeapNumber allocation: The slot dedicated to the seed variable in the script context points to a standard, immutable HeapNumber. Each time the Math.random function updates seed, a new HeapNumber object has to be allocated on the heap resulting in significant allocation and garbage collection pressure.
Floating-point arithmetic: Even though the calculations within Math.random are fundamentally integer operations (using bitwise shifts and additions), the compiler can't take full advantage of this. Because seed is stored as a generic HeapNumber, the generated code uses slower floating-point instructions. The compiler can't prove that seed will always hold a value representable as an integer. While the compiler could potentially speculate about 32-bit integer ranges, V8 primarily focuses on SMIs. Even with 32-bit integer speculation, a potentially costly conversion from 64-bit floating-point to 32-bit integer, along with a lossless check, would still be necessary.
The solution #
To address these issues, we implemented a two-part optimization:
Slot type tracking / mutable heap number slots: We extended script context const value tracking (let-variables that were initialized but never modified) to include type information. We track whether that slot value is constant, a SMI, a HeapNumber or a generic tagged value. We also introduced the concept of mutable heap number slots within script contexts, similar to mutable heap number fields for JSObjects. Instead of pointing to an immutable HeapNumber, the script context slot owns the HeapNumber, and it should not leak its address. This eliminates the need to allocate a new HeapNumber on every update for optimized code. The owned HeapNumber itself is modified in-place.
Mutable heap Int32: We enhance the script context slot types to track whether a numeric value falls within the Int32 range. If it does, the mutable HeapNumber stores the value as a raw Int32. If needed, the transition to a double carries the added benefit of not requiring HeapNumber reallocation. In the case of Math.random, the compiler can now observe that seed is consistently being updated with integer operations and mark the slot as containing a mutable Int32.
 Slot type state machine. A green arrow indicates a transition triggered by storing an
Slot type state machine. A green arrow indicates a transition triggered by storing an SMI value. Blue arrows represent transitions by storing an Int32 value, and red arrows, a double-precision floating-point value. The Other state acts as a sink state, preventing further transitions.It's important to note that these optimizations introduce a code dependency on the type of the value stored in the context slot. The optimized code generated by the JIT compiler relies on the slot containing a specific type (here, an Int32). If any code writes a value to the seed slot that changes its type (e.g., writing a floating-point number or a string), the optimized code will need to deoptimize. This deoptimization is necessary to ensure correctness. Therefore, the stability of the type stored in the slot is crucial for maintaining peak performance. In the case of Math.random, the bitmasking in the algorithm ensures that the seed variable always holds an Int32 value.
The results #
These changes significantly speed up the peculiar Math.random function:
No allocation / fast in-place updates: The seed value is updated directly within its mutable slot in the script context. No new objects are allocated during the Math.random execution.
Integer operations: The compiler, armed with the knowledge that the slot contains an Int32, can generate highly optimized integer instructions (shifts, adds, etc.). This avoids the overhead of floating-point arithmetic.
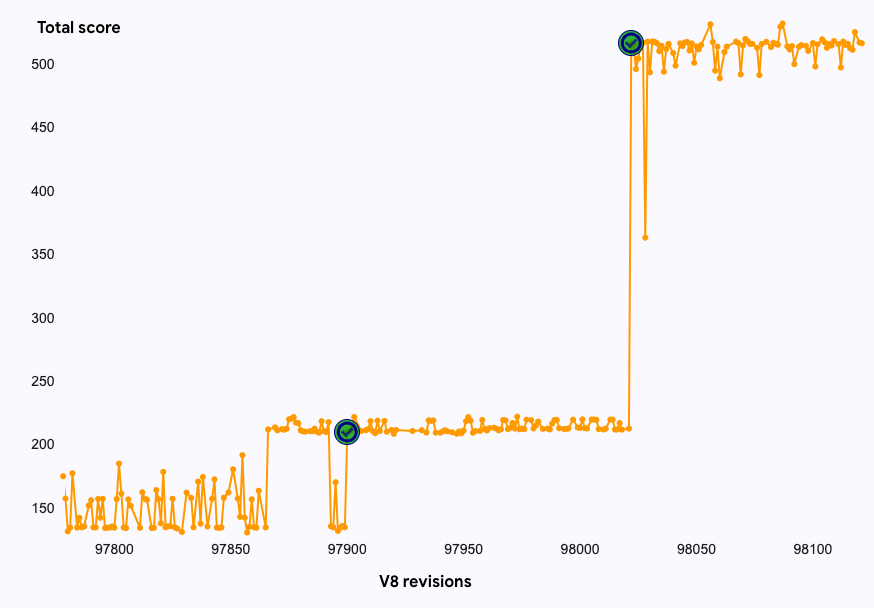
async-fs benchmark results on a Mac M1. Higher scores are better.The combined effect of these optimizations is a remarkable ~2.5x speedup on the async-fs benchmark. This, in turn, contributes to a ~1.6% improvement in the overall JetStream2 score. This demonstrates that seemingly simple code can create unexpected performance bottlenecks, and that small, targeted optimizations can have large impact not just for the benchmark.