V8 v6.9 includes Liftoff, a new baseline compiler for WebAssembly. Liftoff is now enabled by default on desktop systems. This article details the motivation to add another compilation tier and describes the implementation and performance of Liftoff. Logo for Liftoff, V8’s WebAssembly baseline compiler
Logo for Liftoff, V8’s WebAssembly baseline compiler
Since WebAssembly launched more than a year ago, adoption on the web has been steadily increasing. Big applications targeting WebAssembly have started to appear. For example, Epic’s ZenGarden benchmark comprises a 39.5 MB WebAssembly binary, and AutoDesk ships as a 36.8 MB binary. Since compilation time is essentially linear in the binary size, these applications take a considerable time to start up. On many machines it’s more than 30 seconds, which does not provide a great user experience.
But why does it take this long to start up a WebAssembly app, if similar JS apps start up much faster? The reason is that WebAssembly promises to deliver predictable performance, so once the app is running, you can be sure to consistently meet your performance goals (e.g. rendering 60 frames per second, no audio lag or artifacts…). In order to achieve this, WebAssembly code is compiled ahead of time in V8, to avoid any compilation pause introduced by a just-in-time compiler that could result in visible jank in the app.
The existing compilation pipeline (TurboFan) #
V8’s approach to compiling WebAssembly has relied on TurboFan, the optimizing compiler we designed for JavaScript and asm.js. TurboFan is a powerful compiler with a graph-based intermediate representation (IR) suitable for advanced optimizations such as strength reduction, inlining, code motion, instruction combining, and sophisticated register allocation. TurboFan’s design supports entering the pipeline very late, nearer to machine code, which bypasses many of the stages necessary for supporting JavaScript compilation. By design, transforming WebAssembly code into TurboFan’s IR (including SSA-construction) in a straightforward single pass is very efficient, partially due to WebAssembly’s structured control flow. Yet the backend of the compilation process still consumes considerable time and memory.
The new compilation pipeline (Liftoff) #
The goal of Liftoff is to reduce startup time for WebAssembly-based apps by generating code as fast as possible. Code quality is secondary, as hot code is eventually recompiled with TurboFan anyway. Liftoff avoids the time and memory overhead of constructing an IR and generates machine code in a single pass over the bytecode of a WebAssembly function. The Liftoff compilation pipeline is much simpler compared to the TurboFan compilation pipeline.
The Liftoff compilation pipeline is much simpler compared to the TurboFan compilation pipeline.
From the diagram above it is obvious that Liftoff should be able to generate code much faster than TurboFan since the pipeline only consists of two stages. In fact, the function body decoder does a single pass over the raw WebAssembly bytes and interacts with the subsequent stage via callbacks, so code generation is performed while decoding and validating the function body. Together with WebAssembly’s streaming APIs, this allows V8 to compile WebAssembly code to machine code while downloading over the network.
Code generation in Liftoff #
Liftoff is a simple code generator, and fast. It performs only one pass over the opcodes of a function, generating code for each opcode, one at a time. For simple opcodes like arithmetics, this is often a single machine instruction, but can be more for others like calls. Liftoff maintains metadata about the operand stack in order to know where the inputs of each operation are currently stored. This virtual stack exists only during compilation. WebAssembly’s structured control flow and validation rules guarantee that the location of these inputs can be statically determined. Thus an actual runtime stack onto which operands are pushed and popped is not necessary. During execution, each value on the virtual stack will either be held in a register or be spilled to the physical stack frame of that function. For small integer constants (generated by i32.const), Liftoff only records the constant’s value in the virtual stack and does not generate any code. Only when the constant is used by a subsequent operation, it is emitted or combined with the operation, for example by directly emitting a addl <reg>, <const> instruction on x64. This avoids ever loading that constant into a register, resulting in better code.
Let’s go through a very simple function to see how Liftoff generates code for that.
This example function takes two parameters and returns their sum. When Liftoff decodes the bytes of this function, it first begins by initializing its internal state for the local variables according to the calling convention for WebAssembly functions. For x64, V8’s calling convention passes the two parameters in the registers rax and rdx.
For get_local instructions, Liftoff does not generate any code, but instead just updates its internal state to reflect that these register values are now pushed on the virtual stack. The i32.add instruction then pops the two registers and chooses a register for the result value. We cannot use any of the input registers for the result, since both registers still appear on the stack for holding the local variables. Overwriting them would change the value returned by a later get_local instruction. So Liftoff picks a free register, in this case rcx, and produce the sum of rax and rdx into that register. rcx is then pushed onto the virtual stack.
After the i32.add instruction, the function body is finished, so Liftoff must assemble the function return. As our example function has one return value, validation requires that there must be exactly one value on the virtual stack at the end of the function body. So Liftoff generates code that moves the return value held in rcx into the proper return register rax and then returns from the function.
For the sake of simplicity, the example above does not contain any blocks (if, loop …) or branches. Blocks in WebAssembly introduce control merges, since code can branch to any parent block, and if-blocks can be skipped. These merge points can be reached from different stack states. Following code, however, has to assume a specific stack state to generate code. Thus, Liftoff snapshots the current state of the virtual stack as the state which will be assumed for code following the new block (i.e. when returning to the control level where we currently are). The new block will then continue with the currently active state, potentially changing where stack values or locals are stored: some might be spilled to the stack or held in other registers. When branching to another block or ending a block (which is the same as branching to the parent block), Liftoff must generate code that adapts the current state to the expected state at that point, such that the code emitted for the target we branch to finds the right values where it expects them. Validation guarantees that the height of the current virtual stack matches the height of the expected state, so Liftoff need only generate code to shuffle values between registers and/or the physical stack frame as shown below.
Let’s look at an example of that.
The example above assumes a virtual stack with two values on the operand stack. Before starting the new block, the top value on the virtual stack is popped as argument to the if instruction. The remaining stack value needs to be put in another register, since it is currently shadowing the first parameter, but when branching back to this state we might need to hold two different values for the stack value and the parameter. In this case Liftoff chooses to deduplicate it into the rcx register. This state is then snapshotted, and the active state is modified within the block. At the end of the block, we implicitly branch back to the parent block, so we merge the current state into the snapshot by moving register rbx into rcx and reloading register rdx from the stack frame.
Tiering up from Liftoff to TurboFan #
With Liftoff and TurboFan, V8 now has two compilation tiers for WebAssembly: Liftoff as the baseline compiler for fast startup and TurboFan as optimizing compiler for maximum performance. This poses the question of how to combine the two compilers to provide the best overall user experience.
For JavaScript, V8 uses the Ignition interpreter and the TurboFan compiler and employs a dynamic tier-up strategy. Each function is first executed in Ignition, and if the function becomes hot, TurboFan compiles it into highly-optimized machine code. A similar approach could also be used for Liftoff, but the tradeoffs are a bit different here:
- WebAssembly does not require type feedback to generate fast code. Where JavaScript greatly benefits from gathering type feedback, WebAssembly is statically typed, so the engine can generate optimized code right away.
- WebAssembly code should run predictably fast, without a lengthy warm-up phase. One of the reasons applications target WebAssembly is to execute on the web with predictable high performance. So we can neither tolerate running suboptimal code for too long, nor do we accept compilation pauses during execution.
- An important design goal of the Ignition interpreter for JavaScript is to reduce memory usage by not compiling functions at all. Yet we found that an interpreter for WebAssembly is far too slow to deliver on the goal of predictably fast performance. We did, in fact, build such an interpreter, but being 20× or more slower than compiled code, it is only useful for debugging, regardless of how much memory it saves. Given this, the engine must store compiled code anyway; in the end it should store only the most compact and most efficient code, which is TurboFan optimized code.
From these constraints we concluded that dynamic tier-up is not the right tradeoff for V8’s implementation of WebAssembly right now, since it would increase code size and reduce performance for an indeterminate time span. Instead, we chose a strategy of eager tier-up. Immediately after Liftoff compilation of a module finished, the WebAssembly engine starts background threads to generate optimized code for the module. This allows V8 to start executing code quickly (after Liftoff finished), but still have the most performant TurboFan code available as early as possible.
The picture below shows the trace of compiling and executing the EpicZenGarden benchmark. It shows that right after Liftoff compilation we can instantiate the WebAssembly module and start executing it. TurboFan compilation still takes several more seconds, so during that tier-up period the observed execution performance gradually increases since individual TurboFan functions are used as soon as they are finished.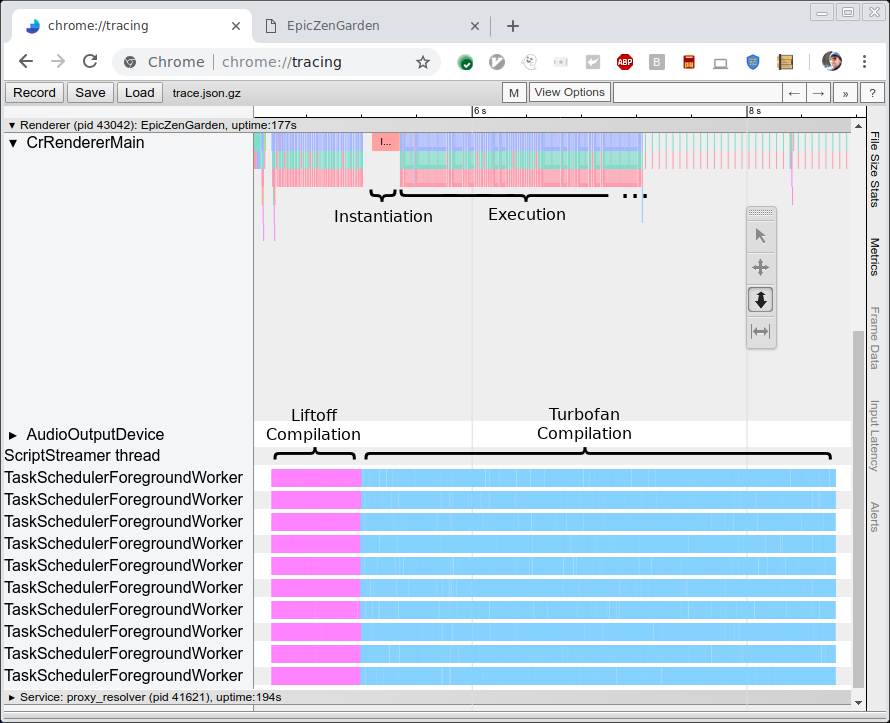
Two metrics are interesting for evaluating the performance of the new Liftoff compiler. First we want to compare the compilation speed (i.e. time to generate code) with TurboFan. Second, we want to measure the performance of the generated code (i.e. execution speed). The first measure is the more interesting here, since the goal of Liftoff is to reduce startup time by generating code as quickly as possible. On the other hand, the performance of the generated code should still be pretty good since that code might still execute for several seconds or even minutes on low-end hardware.
For measuring the compiler performance itself, we ran a number of benchmarks and measured the raw compilation time using tracing (see picture above). We run both benchmarks on an HP Z840 machine (2 x Intel Xeon E5-2690 @2.6GHz, 24 cores, 48 threads) and on a Macbook Pro (Intel Core i7-4980HQ @2.8GHz, 4 cores, 8 threads). Note that Chrome does currently not use more than 10 background threads, so most of the cores of the Z840 machine are unused.
We execute three benchmarks:
- EpicZenGarden: The ZenGarden demo running on the Epic framework
- Tanks!: A demo of the Unity engine
- AutoDesk
- PSPDFKit
For each benchmark, we measure the raw compilation time using the tracing output as shown above. This number is more stable than any time reported by the benchmark itself, as it does not rely on a task being scheduled on the main thread and does not include unrelated work like creating the actual WebAssembly instance.
The graphs below show the results of these benchmarks. Each benchmark was executed three times, and we report the average compilation time. Code generation performance of Liftoff vs. TurboFan on a MacBook
Code generation performance of Liftoff vs. TurboFan on a MacBook Code generation performance of Liftoff vs. TurboFan on a Z840
Code generation performance of Liftoff vs. TurboFan on a Z840
As expected, the Liftoff compiler generates code much faster both on the high-end desktop workstation as well as on the MacBook. The speedup of Liftoff over TurboFan is even bigger on the less-capable MacBook hardware.
Even though performance of the generated code is a secondary goal, we want to preserve user experience with high performance in the startup phase, as Liftoff code might execute for several seconds before TurboFan code is finished.
For measuring Liftoff code performance, we turned off tier-up in order to measure pure Liftoff execution. In this setup, we execute two benchmarks:
Unity headless benchmarks
This is a number of benchmarks running in the Unity framework. They are headless, hence can be executed in the d8 shell directly. Each benchmark reports a score, which is not necessarily proportional to the execution performance, but good enough to compare the performance.
PSPDFKit
This benchmark reports the time it takes to perform different actions on a pdf document and the time it takes to instantiate the WebAssembly module (including compilation).
Just as before, we execute each benchmark three times and use the average of the three runs. Since the scale of the recorded numbers differs significantly between the benchmarks, we report the relative performance of Liftoff vs. TurboFan. A value of +30% means that Liftoff code runs 30% slower than TurboFan. Negative numbers indicate that Liftoff executes faster. Here are the results: Liftoff Performance on Unity
Liftoff Performance on Unity
On Unity, Liftoff code execute on average around 50% slower than TurboFan code on the desktop machine and 70% slower on the MacBook. Interestingly, there is one case (Mandelbrot Script) where Liftoff code outperforms TurboFan code. This is likely an outlier where, for example, the register allocator of TurboFan is doing poorly in a hot loop. We are investigating to see if TurboFan can be improved to handle this case better. Liftoff Performance on PSPDFKit
Liftoff Performance on PSPDFKit
On the PSPDFKit benchmark, Liftoff code executes 18-54% slower than optimized code, while initialization improves significantly, as expected. These numbers show that for real-world code which also interacts with the browser via JavaScript calls, the performance loss of unoptimized code is generally lower than on more computation-intensive benchmarks.
And again, note that for these numbers we turned off tier-up completely, so we only ever executed Liftoff code. In production configurations, Liftoff code will gradually be replaced by TurboFan code, such that the lower performance of Liftoff code lasts only for short period of time.
Future work #
After the initial launch of Liftoff, we are working to further improve startup time, reduce memory usage, and bring the benefits of Liftoff to more users. In particular, we are working on improving the following things:
- Port Liftoff to arm and arm64 to also use it on mobile devices. Currently, Liftoff is only implemented for Intel platforms (32 and 64 bit), which mostly captures desktop use cases. In order to also reach mobile users, we will port Liftoff to more architectures.
- Implement dynamic tier-up for mobile devices. Since mobile devices tend to have much less memory available than desktop systems, we need to adapt our tiering strategy for these devices. Just recompiling all functions with TurboFan easily doubles the memory needed to hold all code, at least temporarily (until Liftoff code is discarded). Instead, we are experimenting with a combination of lazy compilation with Liftoff and dynamic tier-up of hot functions in TurboFan.
- Improve performance of Liftoff code generation. The first iteration of an implementation is rarely the best one. There are several things which can be tuned to speed up the compilation speed of Liftoff even more. This will gradually happen over the next releases.
- Improve performance of Liftoff code. Apart from the compiler itself, the size and speed of the generated code can also be improved. This will also happen gradually over the next releases.
Conclusion #
V8 now contains Liftoff, a new baseline compiler for WebAssembly. Liftoff vastly reduces start-up time of WebAssembly applications with a simple and fast code generator. On desktop systems, V8 still reaches maximum peak performance by recompiling all code in the background using TurboFan. Liftoff is enabled by default in V8 v6.9 (Chrome 69), and can be controlled explicitly with the --liftoff/--no-liftoff and chrome://flags/#enable-webassembly-baseline flags in each, respectively.