Code caching (also known as bytecode caching) is an important optimization in browsers. It reduces the start-up time of commonly visited websites by caching the result of parsing + compilation. Most popular browsers implement some form of code caching, and Chrome is no exception. Indeed, we’ve written and talked about how Chrome and V8 cache compiled code in the past.
In this blog post, we offer a few pieces of advice for JS developers who want to make the best use of code caching to improve the startup of their websites. This advice focuses on the implementation of caching in Chrome/V8, but most of it is likely transferable to other browsers’ code caching implementations too.
Code caching recap #
While other blog posts and presentations offer more detail on our code caching implementation, it’s worthwhile having a quick recap of how things work. Chrome has two levels of caching for V8 compiled code (both classic scripts and module scripts): a low-cost “best effort” in-memory cache maintained by V8 (the Isolate cache), and a full serialized on-disk cache.
The Isolate cache operates on scripts compiled in the same V8 Isolate (i.e. same process, roughly “the same website’s pages when navigating in the same tab”). It is “best-effort” in the sense that it tries to be as fast and as minimal as possible, using data already available to us, at the cost of a potentially lower hit-rate and lack of caching across processes.
- When V8 compiles a script, the compiled bytecode is stored in a hashtable (on the V8 heap), keyed by the script’s source code.
- When Chrome asks V8 to compile another script, V8 first checks if that script’s source code matches anything in this hashtable. If yes, we simply return the existing bytecode.
This cache is fast and effectively free, yet we observe it getting an 80% hit rate in the real world.
The on-disk code cache is managed by Chrome (specifically, by Blink), and it fills the gap that the Isolate cache cannot: sharing code caches between processes, and between multiple Chrome sessions. It takes advantage of the existing HTTP resource cache, which manages caching and expiring data received from the web.
- When a JS file is first requested (i.e. a cold run), Chrome downloads it and gives it to V8 to compile. It also stores the file in the browser’s on-disk cache.
- When the JS file is requested a second time (i.e. a warm run), Chrome takes the file from the browser cache and once again gives it to V8 to compile. This time, however, the compiled code is serialized, and is attached to the cached script file as metadata.
- The third time (i.e. a hot run), Chrome takes both the file and the file’s metadata from the cache, and hands both to V8. V8 deserializes the metadata and can skip compilation.
In summary: Code caching is split into cold, warm, and hot runs, using the in-memory cache on warm runs and the disk cache on hot runs.
Code caching is split into cold, warm, and hot runs, using the in-memory cache on warm runs and the disk cache on hot runs.
Based on this description, we can give our best tips for improving your website’s use of the code caches.
Tip 1: do nothing #
Ideally, the best thing you as a JS developer can do to improve code caching is “nothing”. This actually means two things: passively doing nothing, and actively doing nothing.
Code caching is, at the end of the day, a browser implementation detail; a heuristic-based data/space trade-off performance optimization, whose implementation and heuristics can (and do!) change regularly. We, as V8 engineers, do our best to make these heuristics work for everyone in the evolving web, and over-optimising for the current code caching implementation details may cause disappointment after a few releases, when those details change. In addition, other JavaScript engines are likely to have different heuristics for their code caching implementation. So in many ways, our best advice for getting code cached is like our advice for writing JS: write clean idiomatic code, and we’ll do our best to optimise how we cache it.
In addition to passively doing nothing, you should also try your best to actively do nothing. Any form of caching is inherently dependent on things not changing, thus doing nothing is the best way of allowing cached data to stay cached. There are a couple of ways you can actively do nothing.
Don’t change code #
This may be obvious, but it’s worth making explicit — whenever you ship new code, that code is not yet cached. Whenever the browser makes an HTTP request for a script URL, it can include the date of the last fetch of that URL, and if the server knows that the file hasn’t changed, it can send back a 304 Not Modified response, which keeps our code cache hot. Otherwise, a 200 OK response updates our cached resource, and clears the code cache, reverting it back to a cold run.
It’s tempting to always push your latest code changes immediately, particularly if you want to measure the impact of a certain change, but for caches it’s much better to leave code be, or at least update it as rarely as possible. Consider imposing a limit of ≤ x deployments per week, where x is the slider you can adjust to trade-off caching vs. staleness.
Don’t change URLs #
Code caches are (currently) associated with the URL of a script, as that makes them easy to look up without having to read the actual script contents. This means that changing the URL of a script (including any query parameters!) creates a new resource entry in our resource cache, and with it a new cold cache entry.
Of course, this can also be used to force cache clearing, though that is also an implementation detail; we may one day decide to associate caches with the source text rather than source URL, and this advice will no longer be valid.
Don’t change execution behavior #
One of the more recent optimizations to our code caching implementation is to only serialize the compiled code after it has executed. This is to try to catch lazily compiled functions, which are only compiled during execution, not during the initial compile.
This optimization works best when each execution of the script executes the same code, or at least the same functions. This can be a problem if you e.g. have A/B tests which are dependent on a runtime decision:
if (Math.random() > 0.5) {
A();
} else {
B();
}
In this case, only A() or B() is compiled and executed on the warm run, and entered into the code cache, yet either could be executed in subsequent runs. Instead, try to keep your execution deterministic to keep it on the cached path.
Tip 2: do something #
Certainly the advice to do “nothing”, whether passively or actively, is not very satisfying. So in addition to doing “nothing”, given our current heuristics and implementation, there are some things you can do. Please remember, though, that heuristics can change, this advice may change, and there is no substitute for profiling.
Split out libraries from code using them #
Code caching is done on a coarse, per-script basis, meaning that changes to any part of the script invalidate the cache for the entire script. If your shipping code consists of both stable and changing parts in a single script, e.g. libraries and business logic, then changes to the business logic code invalidate the cache of the library code.
Instead, you can split out the stable library code into a separate script, and include it separately. Then, the library code can be cached once, and stay cached when the business logic changes.
This has additional benefits if the libraries are shared across different pages on your website: since the code cache is attached to the script, the code cache for the libraries is also shared between pages.
Merge libraries into code using them #
Code caching is done after each script is executed, meaning that the code cache of a script will include exactly those functions in that script that were compiled when the script finishes executing. This has several important consequences for library code:
- The code cache won’t include functions from earlier scripts.
- The code cache won’t include lazily compiled functions called by later scripts.
In particular, if a library consists of entirely lazily compiled functions, those functions won’t be cached even if they are used later.
One solution to this is to merge libraries and their uses into a single script, so that the code caching “sees” which parts of the library are used. This is unfortunately the exact opposite of the advice above, because there are no silver bullets. In general, we don’t recommend merging all your scripts JS into a single large bundle; splitting it up into multiple smaller scripts tends to be more beneficial overall for reasons other than code caching (e.g. multiple network requests, streaming compilation, page interactivity, etc.).
Take advantage of IIFE heuristics #
Only the functions that are compiled by the time the script finishes executing count towards the code cache, so there are many kinds of function that won’t be cached despite executing at some later point. Event handlers (even onload), promise chains, unused library functions, and anything else that is lazily compiled without being called by the time </script> is seen, all stays lazy and is not cached.
One way to force these functions to be cached is to force them to be compiled, and a common way of forcing compilation is by using IIFE heuristics. IIFEs (immediately-invoked function expressions) are a pattern where a function is called immediately after being created:
(function foo() {
})();
Since IIFEs are called immediately, most JavaScript engines try to detect them and compile them immediately, to avoid paying the cost of lazy compilation followed by full compilation. There are various heuristics to detect IIFEs early (before the function has to be parsed), the most common being a ( before the function keyword.
Since this heuristic is applied early, it triggers a compile even if the function is not actually immediately invoked:
const foo = function() {
};
const bar = (function() {
});
This means that functions that should be in the code cache can be forced into it by wrapping them in parentheses. This can, however, make startup time suffer if the hint is applied incorrectly, and in general this is somewhat of an abuse of heuristics, so our advice is to avoid doing this unless it is necessary.
Group small files together #
Chrome has a minimum size for code caches, currently set to 1 KiB of source code. This means that smaller scripts are not cached at all, since we consider the overheads to be greater than the benefits.
If your website has many such small scripts, the overhead calculation may not apply in the same way anymore. You may want to consider merging them together so that they exceed the minimum code size, as well as benefiting from generally reducing script overheads.
Avoid inline scripts #
Script tags whose source is inline in the HTML do not have an external source file that they are associated with, and therefore can’t be cached with the above mechanism. Chrome does try to cache inline scripts, by attaching their cache to the HTML document’s resource, but these caches then become dependent on the entire HTML document not changing, and are not shared between pages.
So, for non-trivial scripts which could benefit from code caching, avoid inlining them into the HTML, and prefer to include them as external files.
Use service worker caches #
Service workers are a mechanism for your code to intercept network requests for resources in your page. In particular, they let you build a local cache of some of your resources, and serve the resource from cache whenever they are requested. This is particularly useful for pages that want to continue to work offline, such as PWAs.
A typical example of a site using a service worker registers the service worker in some main script file:
navigator.serviceWorker.register('/sw.js');
And the service worker adds event handlers for installation (creating a cache) and fetching (serving resources, potentially from cache).
self.addEventListener('install', (event) => {
async function buildCache() {
const cache = await caches.open(cacheName);
return cache.addAll([
'/main.css',
'/main.mjs',
'/offline.html',
]);
}
event.waitUntil(buildCache());
});
self.addEventListener('fetch', (event) => {
async function cachedFetch(event) {
const cache = await caches.open(cacheName);
let response = await cache.match(event.request);
if (response) return response;
response = await fetch(event.request);
cache.put(event.request, response.clone());
return response;
}
event.respondWith(cachedFetch(event));
});
These caches can include cached JS resources. However, we have slightly different heuristics for them since we can make different assumptions. Since the service worker cache follows quota-managed storage rules it is more likely to be persisted for longer and the benefit of caching will be greater. In addition, we can infer further importance of resources when they are pre-cached before the load.
The largest heuristic differences take place when the resource is added to the service worker cache during the service worker install event. The above example demonstrates such a use. In this case the code cache is immediately created when the resource is put into the service worker cache. In addition, we generate a "full" code cache for these scripts - we no longer compile functions lazily, but instead compile everything and place it in the cache. This has the advantage of having fast and predictable performance, with no execution order dependencies, though at the cost of increased memory use.
If a JS resource is stored via the Cache API outside of the service worker install event then code cache is not immediately generated. Instead, if a service worker responds with that response from the cache then the "normal" code cache will be generated open first load. This code cache will then be available for consumption on the second load; one load faster than with the typical code caching scenario. Resources may be stored in the Cache API outside the install event when "progressively" caching resources in the fetch event or if the Cache API is updated from the main window instead of the service worker.
Note, the pre-cached "full" code cache assumes the page where the script will be run will use UTF-8 encoding. If the page ends up using a different encoding then the code cache will be discarded and replaced with a "normal" code cache.
In addition, the pre-cached "full" code cache assumes the page will load the script as a classic JS script. If the page ends up loading it as an ES module instead then the code cache will be discarded and replaced with a "normal" code cache.
Tracing #
None of the above suggestions is guaranteed to speed up your web app. Unfortunately, code caching information is not currently exposed in DevTools, so the most robust way to find out which of your web app’s scripts are code-cached is to use the slightly lower-level chrome://tracing.
chrome://tracing records instrumented traces of Chrome during some period of time, where the resulting trace visualization looks something like this: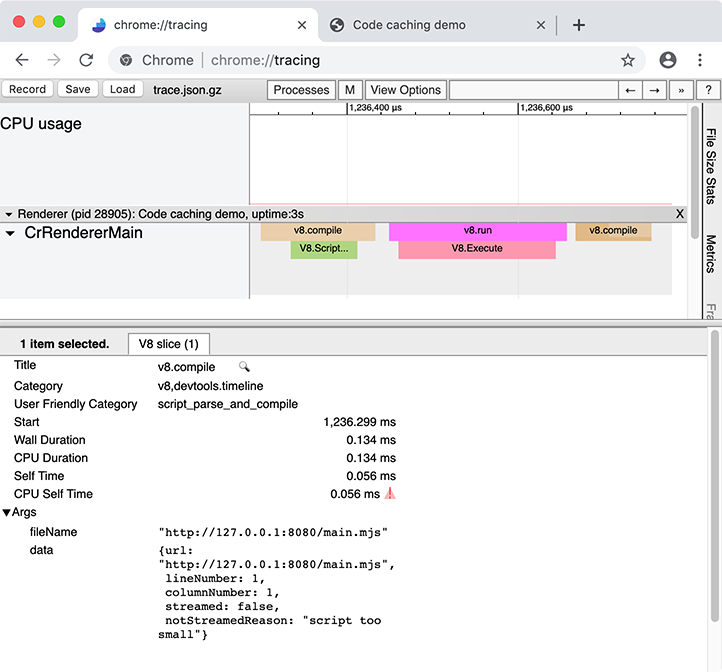 The
The chrome://tracing UI with a recording of a warm cache run
Tracing records the behavior of the entire browser, including other tabs, windows, and extensions, so it works best when done in a clean user profile, with extensions disabled, and with no other browser tabs open:
google-chrome --user-data-dir="$(mktemp -d)" --disable-extensions
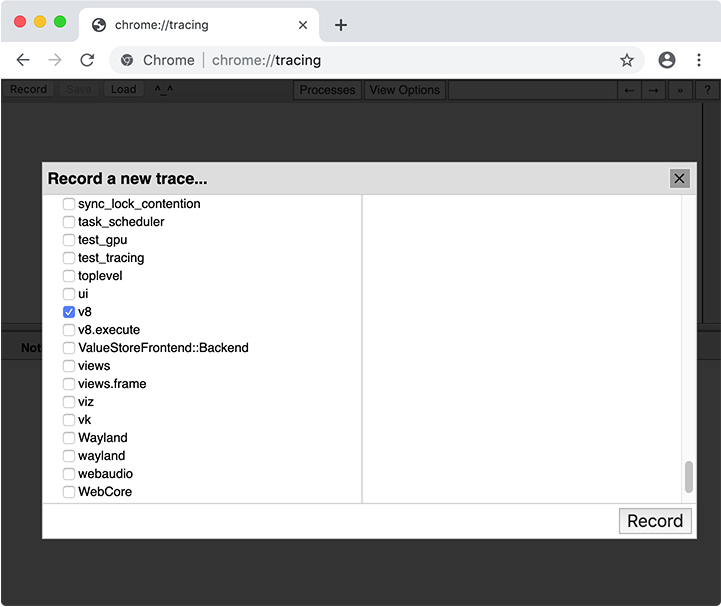
When collecting a trace, you have to select what categories to trace. In most cases you can simply select the “Web developer” set of categories, but you can also pick categories manually. The important category for code caching is v8.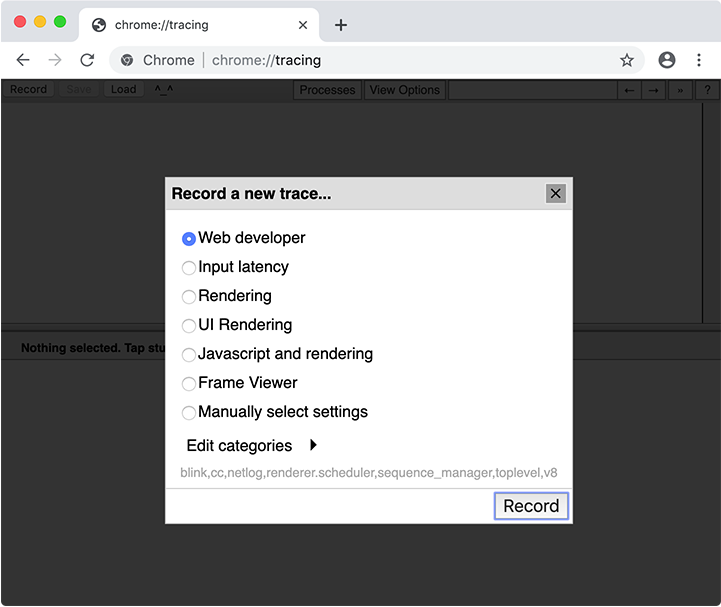
After recording a trace with the v8 category, look for v8.compile slices in the trace. (Alternatively, you could enter v8.compile in the tracing UI’s search box.) These list the file being compiled, and some metadata about the compilation.
On a cold run of a script, there is no information about code caching — this means that the script was not involved in producing or consuming cache data.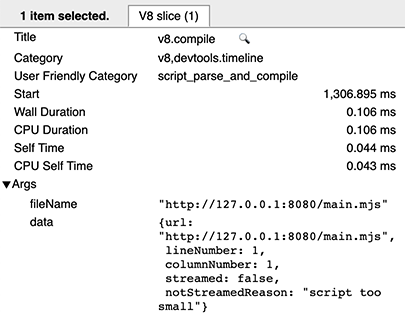
On a warm run, there are two v8.compile entries per script: one for the actual compilation (as above), and one (after execution) for producing the cache. You can recognize the latter as it has cacheProduceOptions and producedCacheSize metadata fields.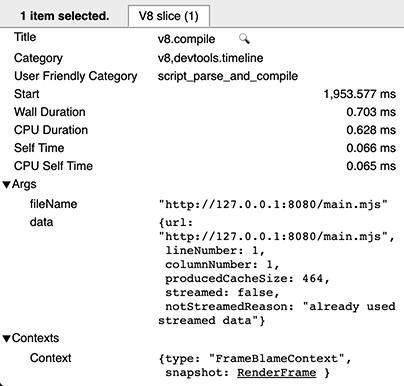
On a hot run, you’ll see a v8.compile entry for consuming the cache, with metadata fields cacheConsumeOptions and consumedCacheSize. All sizes are expressed in bytes.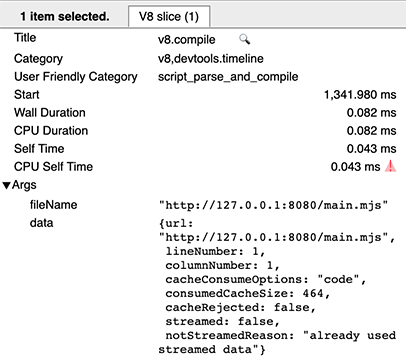
Conclusion #
For most developers, code caching should “just work”. It works best, like any cache, when things stay unchanged, and works on heuristics which can change between versions. Nevertheless, code caching does have behaviors that can be used, and limitations which can be avoided, and careful analysis using chrome://tracing can help you tweak and optimize the use of caches by your web app.